Slides
https://github.com/keypointt/reading/blob/master/spark/2017_spark_spring_SF_FaceBook_Hive_Spark.pdf
note
1. Why bucketing
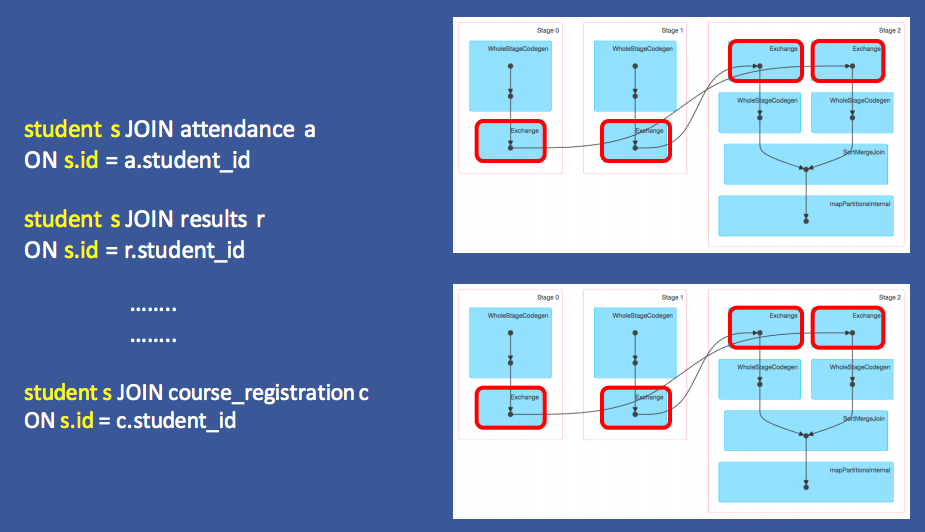
Painpoint: when student table needs to join with multiple other tables on the same id, student table needs to be shuffled (write to and read from disk many times), which is high io/network cost.
Solution: here is to pre-compute at the creation of student table.
Generalize: applicapility domain is, a lot of join operation on the same key, since if using the same key over and over again then no need to shuffled every time.
Result: less CPU, less latency.
2. Bucketing: hive-vs-spark
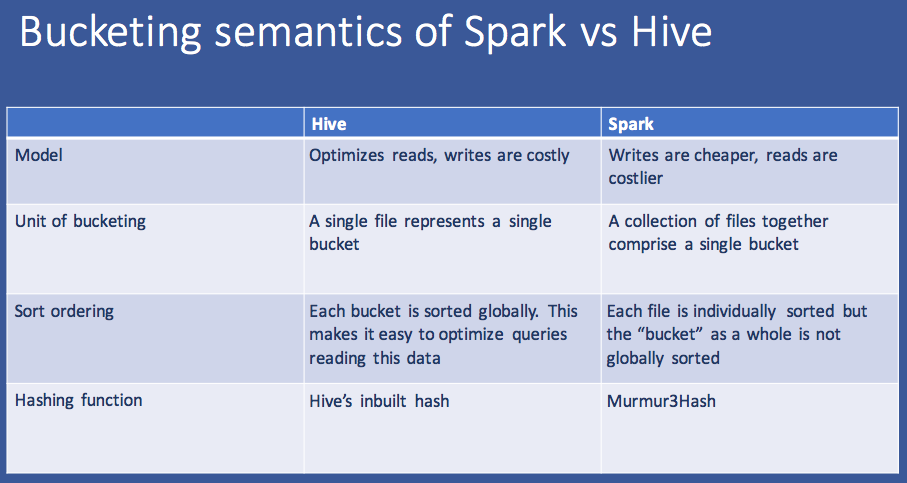
Master Ticket: Hive bucketing support
https://issues.apache.org/jira/browse/SPARK-19256
Reference: