Slides
https://github.com/keypointt/reading/blob/master/spark/2017_spark_spring_SF_PayPal.pdf
note
Paypal Architecture
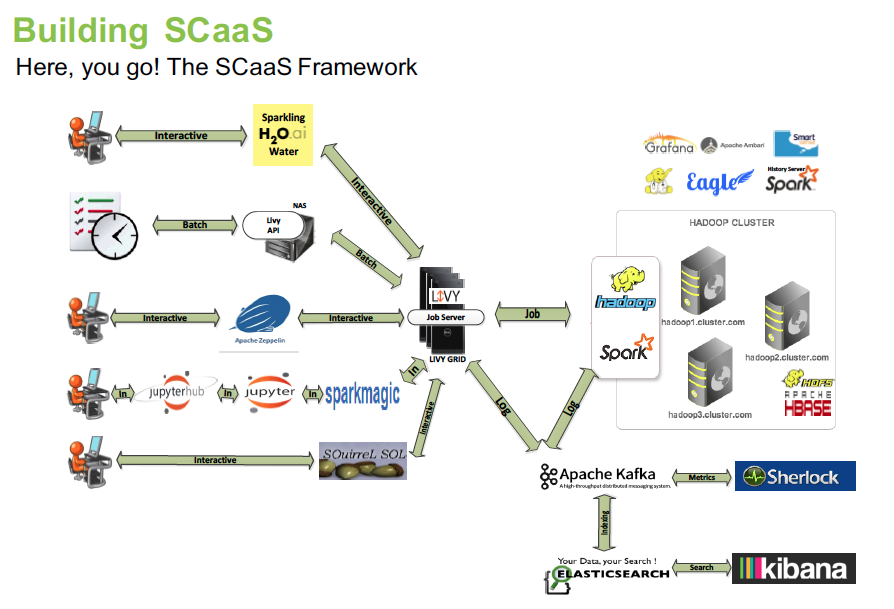
From the graph, it’s clear that LIVY is the core of communication.
The main benefits are REST-easy, sharing cache across whole system. Also, easy for monitoring and metrics tracking. Access log is also centralized.
Open source: LIVY
https://github.com/cloudera/livy
Livy is an open source REST interface for interacting with Apache Spark from anywhere. It supports executing snippets of code or programs in a Spark context that runs locally or in Apache Hadoop YARN.
LIVY PySpark Example
PySpark has the same API, just with a different initial request:
data = {'kind': 'pyspark'}
r = requests.post(host + '/sessions', data=json.dumps(data), headers=headers)
r.json()
{u'id': 1, u'state': u'idle'}
The Pi example from before then can be run as:
data = {
'code': textwrap.dedent("""
import random
NUM_SAMPLES = 100000
def sample(p):
x, y = random.random(), random.random()
return 1 if x*x + y*y < 1 else 0
count = sc.parallelize(xrange(0, NUM_SAMPLES)).map(sample).reduce(lambda a, b: a + b)
print "Pi is roughly %f" % (4.0 * count / NUM_SAMPLES)
""")
}
r = requests.post(statements_url, data=json.dumps(data), headers=headers)
pprint.pprint(r.json())
{u'id': 12,
u'output': {u'data': {u'text/plain': u'Pi is roughly 3.136000'},
u'execution_count': 12,
u'status': u'ok'},
u'state': u'running'}
Reference:
- https://spark-summit.org/2017/events/spark-compute-as-a-service-at-paypal/