Slides
note
User Behavior Anomaly Detection model
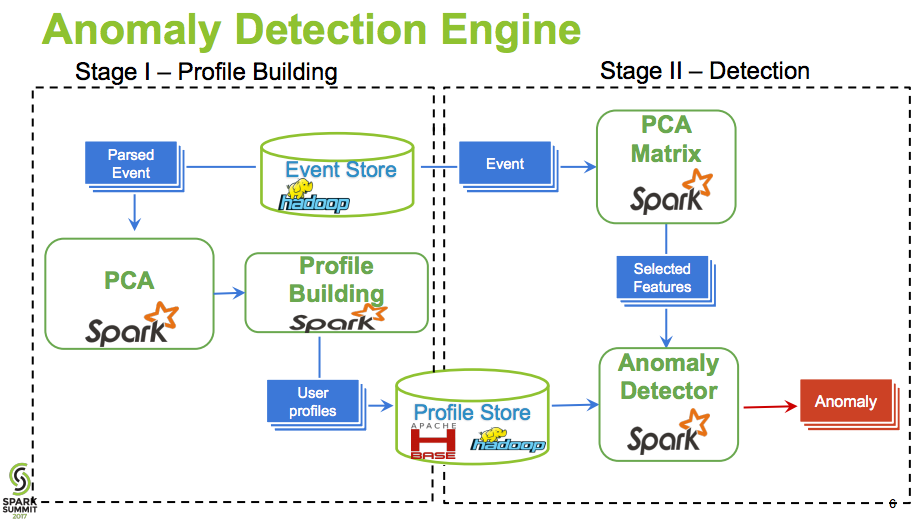
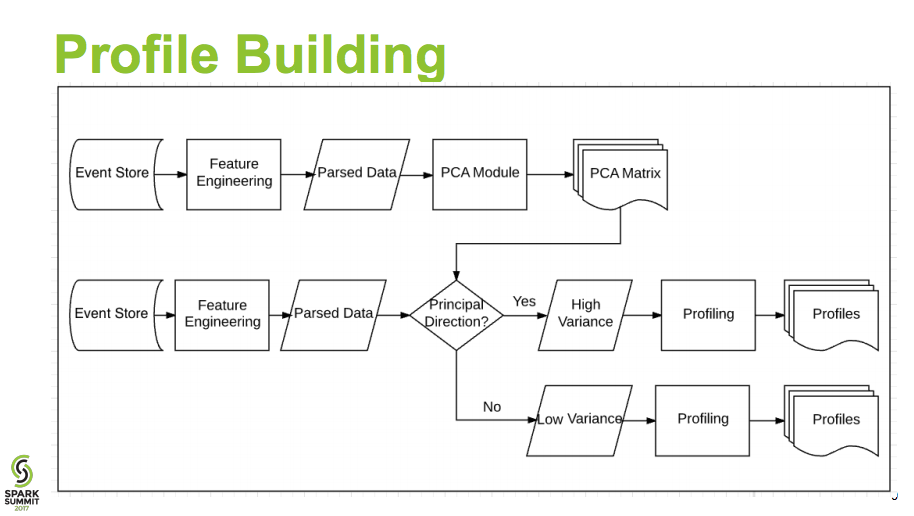
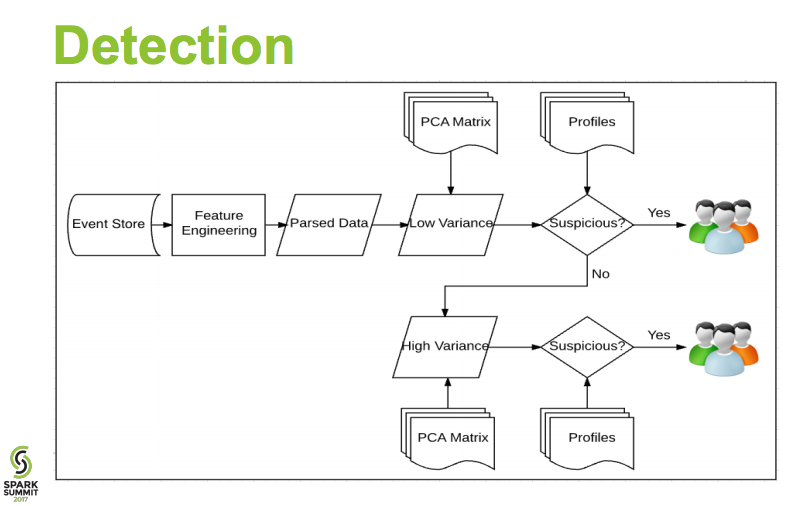
Using PCA to build feature majority, and mapping raw data back to this model for anomaly search. Typical.
I think this topic is missing:
- parsed data is stored in hadoop event store, if this is not streamed, then the whole detection model is off line model.
- simple idea is, compute the PCA vector real-time and update this PCA as streamed data.
- then every new user behavior, compute distance from PCA vector, if above threshold value, then alarm as anomaly. In this case, real time detection.
- did not mention scale issue, or synchronize.
- if, a DDoS like senario, millions of mis-behavior data streamed in contributing to training data, and to take majority of existing training data, then this model could fail.
- if real time, alarm will fire for a while, until huge number of mis-behavior data take over training and detection model.
- if batched, then it’s quite possible that the model could be crashed in one batch, when updated with huge mis-behavior data. In this case, the alarm could be muted completely with no firing.
- if, a DDoS like senario, millions of mis-behavior data streamed in contributing to training data, and to take majority of existing training data, then this model could fail.
- model update and event detection could be slightly un-sync-ed, if profile building process takes longer time to finished or gets queued.
Reference: