A/B testing: Improving the Netflix Streaming Experience
- goal: understand the impact of a new streaming-related algorithm or a change to an existing algorithm
- 1) How does the change (“treatment”) affect QoE(quality of experience) metrics?, and
- 2) What effect does the change have on member behavior:
- do our members prefer the new experience or the old one?
- experiment components
- metrics
- video quality
- rebuffers
- play delay (time between initiating playback and playback start)
- playback errors
- randomized A/B experiments
- client-side adaptive streaming algorithms: networks, network conditions, and device-level limitations
- Content Delivery: Open Connect is Netflix’s Content Delivery Network (CDN)
- Encoding: efficient encodes for low-bandwidth streaming
- metrics
Data Microservices @2015
https://www.infoq.com/presentations/netflix-refactoring/
- Matt Zimmer, ~9 year Netflix tenure https://www.linkedin.com/in/zimmermatt/
- very good point: systems are just throw-away-artifact, and any system is supposed in use for a limited time
- then next question, how to migrate off current system
- migration strategy: migrate chunk by chunk
basically same architecture in https://keypointt.github.io/2020/05/16/Netflix-playback-dive-deep.html , but more of rationale behind why making such design decision.
since anyway, it’s 5 years ago
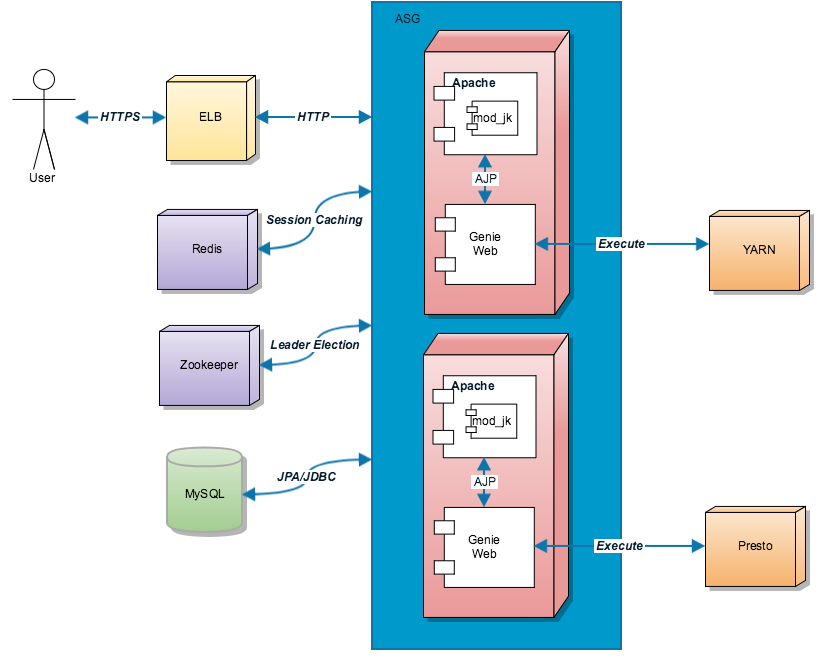
Data platform architecture - Evolving the Netflix Data Platform with Genie 3 @June2017
https://netflixtechblog.com/evolving-the-netflix-data-platform-with-genie-3-598021604dda
- status of June2017
- 150k jobs per day (~700 running at any given time generating ~200 requests per second on average)
- across 40 I2.4XL AWS EC2 instances
- use case
- for users to submit job requests to the jobs API
- leverage Genie’s configuration repository to set up local working directories for local mode execution
Ginie github: https://github.com/Netflix/genie
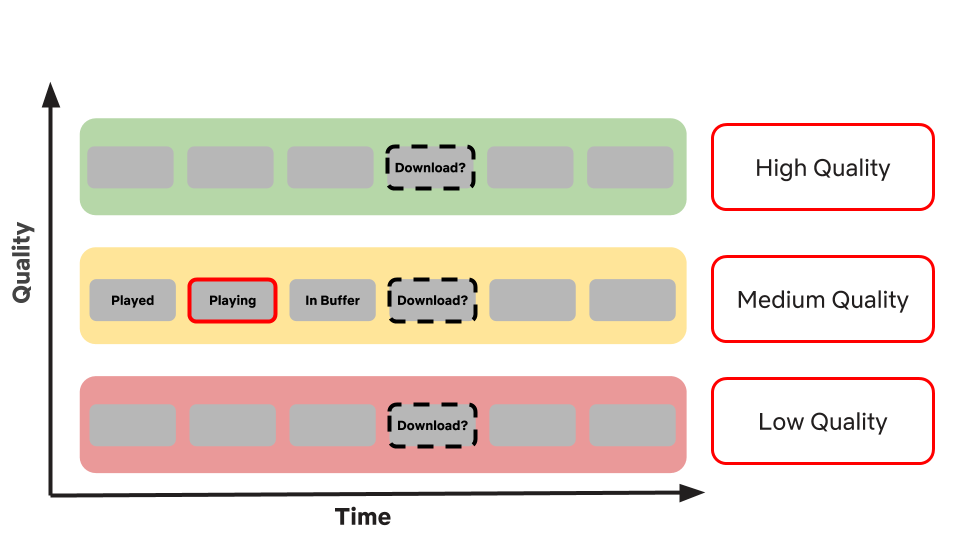
How to improve Streaming Quality @2018
Using Machine Learning to Improve Streaming Quality at Netflix
- https://www.linkedin.com/pulse/using-machine-learning-improve-streaming-quality-chaitanya-ekanadham/
- Chaitanya (Chaitu) Ekanadham https://www.linkedin.com/in/chaitue/
- Network quality characterization and prediction: richer characterization of network quality would prove useful for
- analyzing networks (for targeting/analyzing product improvements),
- determining initial video quality and/or
- adapting video quality throughout playback
- Predictive caching
- Device anomaly detection: UI changes may slowly degrade performance on a particular device
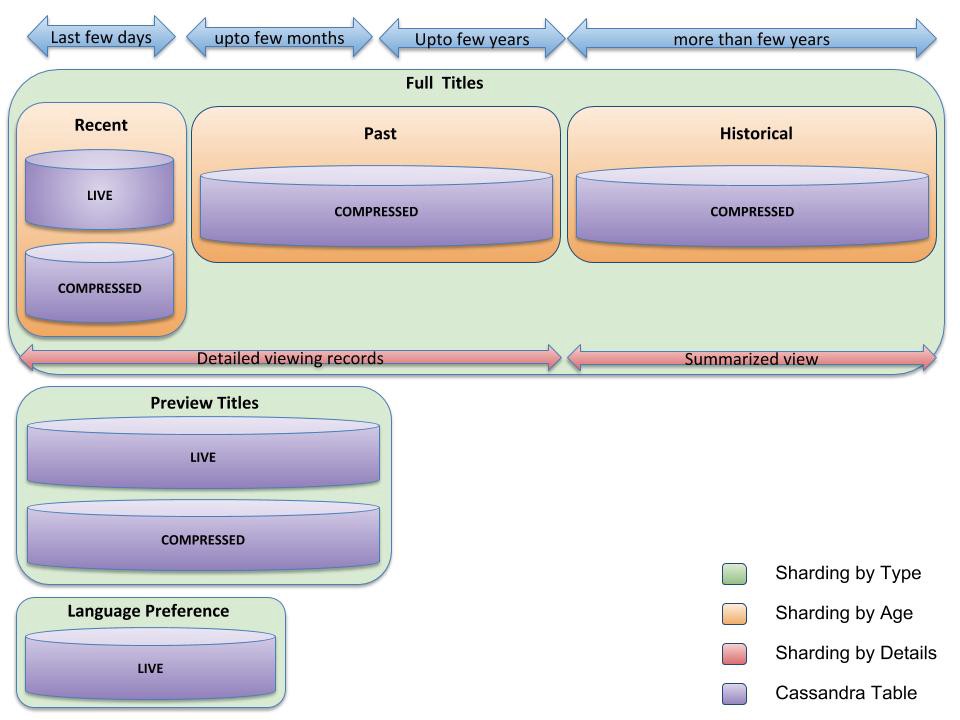
Scaling Time Series Data Storage @2018
Part-1 https://netflixtechblog.com/scaling-time-series-data-storage-part-i-ec2b6d44ba39
V0.1 initial iteration
- Cassandra choice
- good support for time series data
- Time range query to read a time slice of a member’s data
- favors eventual consistency over loss of availability
- read heavy, write to read ratio is about 9:1
- row key:CustomerId
- Partitioning based on CustomerId
- good support for time series data
- Caching Layer: key value store, in front of Cassandra storage
V1.0 Redesign: Live and Compressed Storage Approach
- goal
- Smaller Storage Footprint.
- viewing history data
- Live or Recent Viewing History (LiveVH) - @Xin: kind of hot store and cold store
- Compressed or Archival Viewing History (CompressedVH)
- assumption: updates to CompressedVH are rare
- viewing history data
- Consistent Read/Write Performance as viewing per member grows
- Smaller Storage Footprint.
- Auto Scaling via Chunking
- read metadata, then parallel reading chunks
- also update Caching for chunks
Part-2 https://netflixtechblog.com/scaling-time-series-data-storage-part-ii-d67939655586
V2.0 Redesign
- goal
- Data Category: Shard by data type, Reduce data fields to just the essential elements
- clusters sharded by type/age/level
- Data Age: Shard by age of data. For recent data, expire after a set TTL
- For historical data, archive cluster
- Data Category: Shard by data type, Reduce data fields to just the essential elements
- Performance
- Caching: mimic the backend storage architecture
- close to 99% hit rate
- Caching: mimic the backend storage architecture
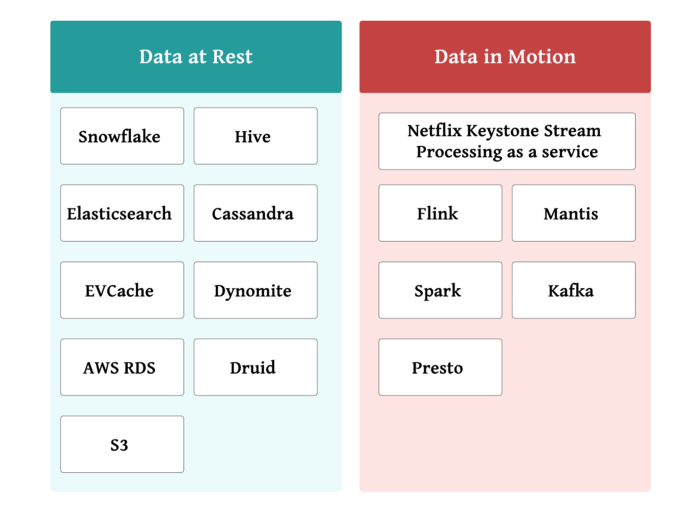
Byte Down: Making Netflix’s Data Infrastructure Cost-Effective
@Xin: basically just AWS-Billing-Insights extension, including aws-budgets and notification
- billing data source
- EC2-based platforms
- S3-based platforms
- a druid-backed custom dashboard to relay cost context
Cost saving: Automated storage recommendations
@Xin: if build up a forecasting model for time series pattern, easy to spot cost saving oppurtunity and set up automatic scale up/down triggering
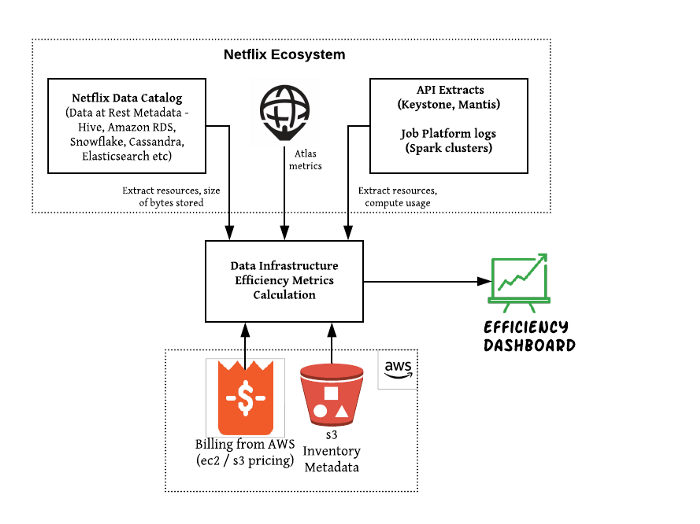
Links:
- https://netflixtechblog.com/byte-down-making-netflixs-data-infrastructure-cost-effective-fee7b3235032
- Netflix-Atlas was developed by Netflix to manage dimensional time series data for near real-time operational insight
- Netflix version AWS-Cloudwatch
- https://github.com/Netflix/atlas/wiki
- Netflix-Mantis: visibility into operational environments
- https://netflixtechblog.com/stream-processing-with-mantis-78af913f51a6
- https://netflixtechblog.com/introducing-atlas-netflixs-primary-telemetry-platform-bd31f4d8ed9a
- Netflix-Metacat: Making Big Data Discoverable and Meaningful at Netflix
- a federated service providing a unified REST/Thrift interface to access metadata of various data stores
- https://netflixtechblog.com/metacat-making-big-data-discoverable-and-meaningful-at-netflix-56fb36a53520
- Amazon S3 inventory: audit and report on the replication and encryption status of your objects for business, compliance, and regulatory needs
- https://docs.aws.amazon.com/AmazonS3/latest/dev/storage-inventory.html
- Apache Druid is a high performance real-time analytics database.
- https://druid.apache.org/
Mastering Chaos - A Netflix Guide to Microservices
Notes
- Fault Injection Testing - framework
- interesting, vaccine ideaology - most deadly case
- Cassandra - eventual consistency
- production ready
- similar to AMZN ops SOP
Links
- https://www.infoq.com/presentations/netflix-chaos-microservices