There is a good summary of all existing ML tools https://github.com/EthicalML/awesome-production-machine-learning
How to choose
- MLFlow if you care more about tracking experiments or tracking and deploying models using MLFlow’s predefined patterns than about finding a tool that can adapt to your existing custom workflows.
- MLeap The mlflow.mleap module provides an API for saving
Spark MLLibmodels using the MLeap persistence mechanism.
- MLeap The mlflow.mleap module provides an API for saving
- KubeFlow if you want to use Kubernetes but still define your tasks with Python instead of YAML. More binding to Google eco-system.
- SageMaker Pipelines continuous integration and continuous delivery (CI/CD) service for ML. More of binding to existing AWS-Sagemaker solution (and AWS eco-system) like notebook, jobs, endpoint serving.
ZenML – An extensible open-source MLOps framework to create reproducible pipelines. https://zenml.io/
Dagster.io – Data orchestrator for machine learning, analytics, and ETL.
MLRun – Generic mechanism for data scientists to build, run, and monitor ML tasks and pipelines. https://github.com/mlrun/mlrun
Kubeflow vs. MLFlow
Kubeflow and MLFlow are both smaller, more specialized tools than general task orchestration platforms such as Airflow or Luigi. Kubeflow relies on Kubernetes, while MLFlow is a Python library that helps you add experiment tracking to your existing machine learning code. Kubeflow lets you build a full DAG where each step is a Kubernetes pod, but MLFlow has built-in functionality to deploy your scikit-learn models to Amazon Sagemaker or Azure ML.
Use Kubeflow if you want to track your machine learning experiments and deploy your solutions in a more customized way, backed by Kubernetes. Use MLFlow if you want a simpler approach to experiment tracking and want to deploy to managed platforms such as Amazon Sagemaker.
DeltaLake
This should be in previous data-processing-tools post, but it’s also tightly coupled with ML concepts.
Also, ML data can be expanded to be a giant topic…
Conditional update without overwrite
Delta Lake provides programmatic APIs to conditional update, delete, and merge (upsert) data into tables. Here are a few examples.
- @Xin: this is important for real life daily operations. as new data refreshed and streamned in for futher processing/training, continues integration for data is also important (not only code deployment CI/CD).
deltaTable.as("oldData")
.merge(
newData.as("newData"),
"oldData.id = newData.id")
.whenMatched
.update(Map("id" -> col("newData.id")))
.whenNotMatched
.insert(Map("id" -> col("newData.id")))
.execute()
Read older versions of data using time travel
You can query previous snapshots of your Delta table by using time travel. If you want to access the data that you overwrote, you can query a snapshot of the table before you overwrote the first set of data using the versionAsOf option.
- @Xin: also important, to reproduce a bug and debug data issues
df = spark.read.format("delta").option("versionAsOf", 0).load("/tmp/delta-table")
df.show()
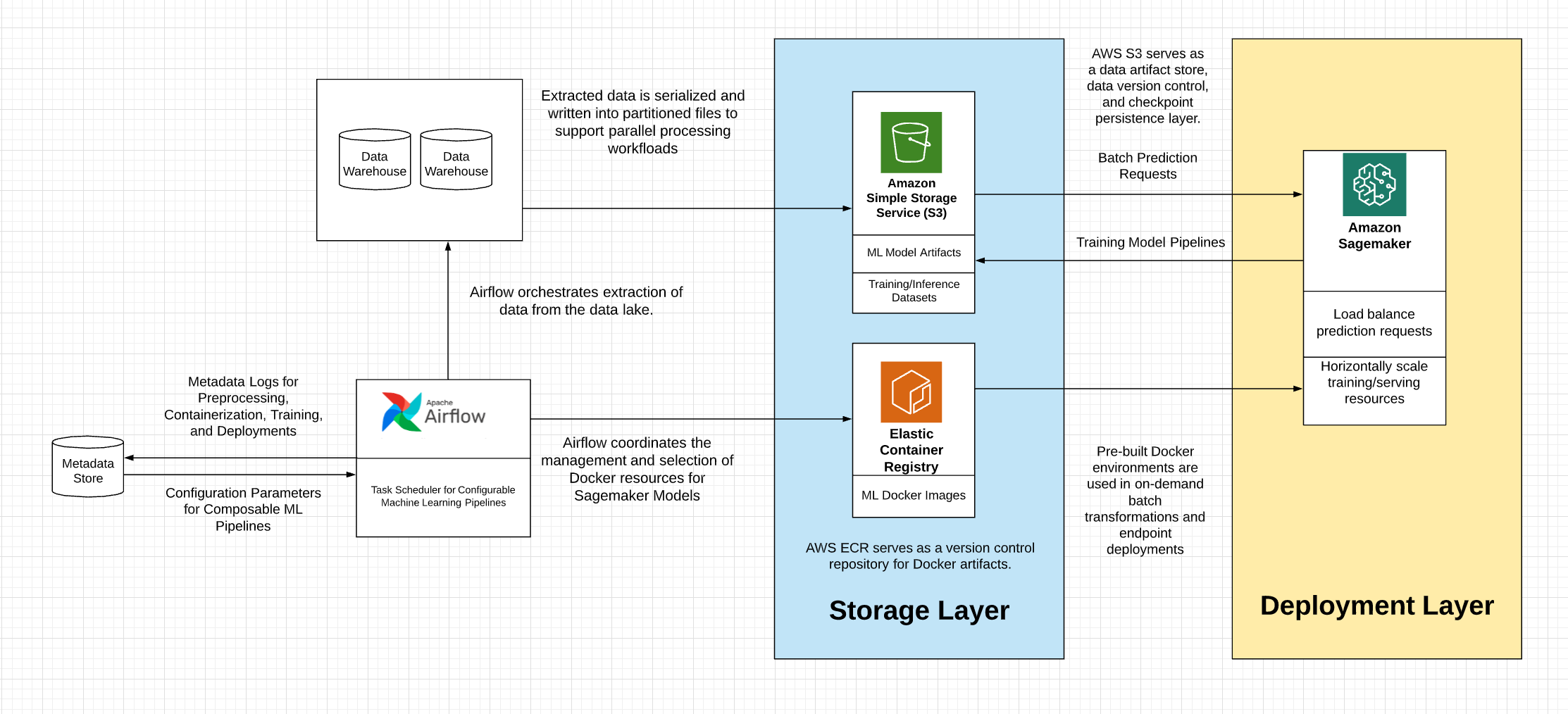
AWS specific orchestration
Glue + SageMaker
Moving from notebooks to automated ML pipelines using Amazon SageMaker and AWS Glue
- Glue trigger:
- Scheduled: A time-based trigger based on cron.\
- Conditional: A trigger that fires when a previous job or crawler or multiple jobs or crawlers satisfy a list of conditions.
- On-demand: A trigger that fires when you activate it.
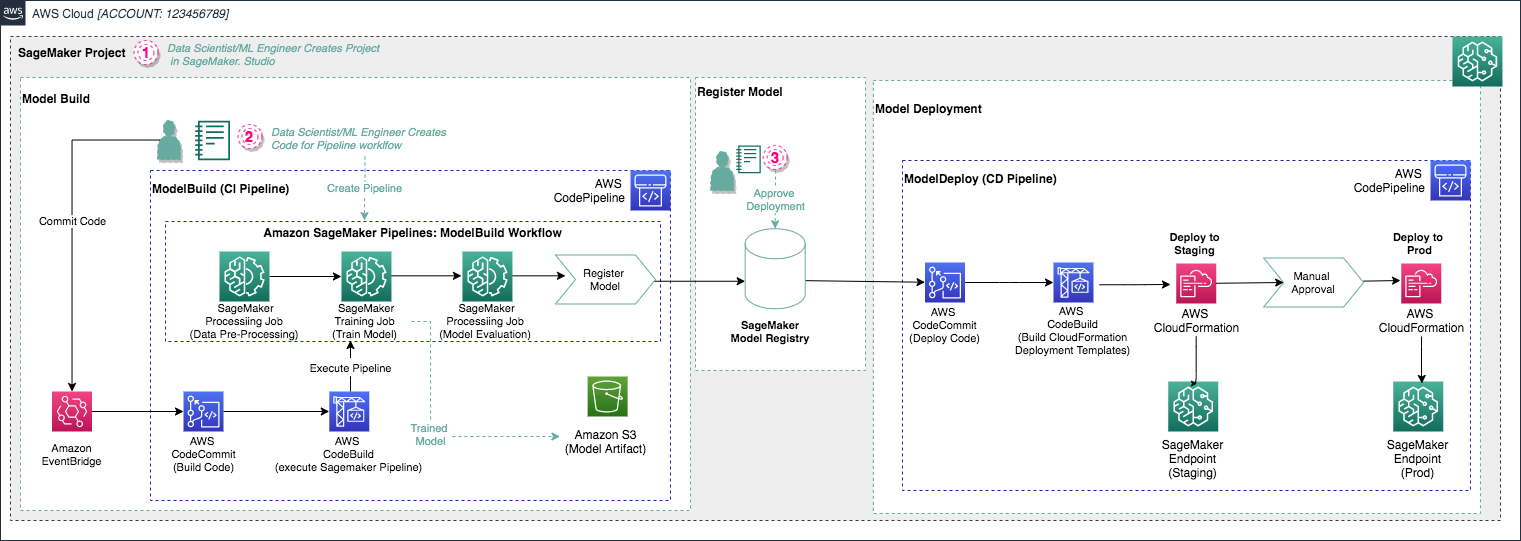
[2021-Release] Amazon SageMaker Pipelines
Building, automating, managing, and scaling ML workflows using Amazon SageMaker Pipelines
purpose-built, easy-to-use continuous integration and continuous delivery (CI/CD) service for machine learning (ML) SageMaker Pipelines is a native workflow orchestration tool for building ML pipelines that take advantage of direct Amazon SageMaker integration
- @Xin: feel like it’s mirror of MLFlow, even for components names, quote
Three components improve the operational resilience and reproducibility of your ML workflows: pipelines, model registry, and projects.
Automatated: MLOps templates and integrations
SageMaker projects introduce MLOps templates that automatically provision the underlying resources needed to enable CI/CD capabilities for your ML development lifecycle.
[2022-Release] AWS Fraud detection service
AWS fraud detector https://aws.amazon.com/fraud-detector/
Tutorials
- https://docs.aws.amazon.com/frauddetector/latest/ug/get-started.html
- https://docs.aws.amazon.com/frauddetector/latest/ug/model-variable-importance.html
Algorithm: Amazon Fraud Detector uses SHapley Additive exPlanations (SHAP)`.
- https://docs.aws.amazon.com/frauddetector/latest/ug/model-variable-importance.html
- Notebook https://github.com/aws-samples/aws-fraud-detector-samples
But, it’s just toooo exapensive……
- https://aws.amazon.com/fraud-detector/pricing/
- I can easily set up an ec2 instance to achive the same with no-limit model endpoint inferences
Uber ML infrastructure - Michelangelo
As I mentioned in previous post, UBER Machine Learning Platform - Michelangelo
Unfortunately, this tool is not open sourced. Just high level architecture is shared publicly.
It has Python ML Model Development module https://eng.uber.com/michelangelo-pyml/
- @Todo
AWS Step-function - Orchestration
I have to say, Step-function is a pretty solid tool, if you are into AWS eco-system.
For this many years, no complain.
Tim Bray got promoted to VP for this, deserve it.
More Airflow vs AWS? in https://stackoverflow.com/questions/64016869/airflow-versus-aws-step-functions-for-workflow
And Amazon Managed Workflows for Apache Airflow (MWAA)
Netflix Orchestration - Metaflow
[Netflix] Genie
https://github.com/Netflix/genie
Genie is a federated Big Data orchestration and execution engine developed by Netflix.
[Netflix] MetaFlow
Metaflow provides a unified API to the infrastructure stack that is required to execute data science projects, from prototype to production.

[Netflix] Metaflow Metadata Service
https://github.com/Netflix/metaflow-service
Facebook - dagger
https://github.com/facebookresearch/dagger
dagger: A Python Framework for Reproducible Machine Learning Experiment Orchestration
Seldon
Seldon makes MLOps software for enterprise deployment of machine learning models.
Seldon Core
An open source platform to deploy your machine learning models on Kubernetes at massive scale.
https://github.com/SeldonIO/seldon-core
Example design for a startup
https://towardsdatascience.com/designing-ml-orchestration-systems-for-startups-202e527d7897