Reference: https://engineeringblog.yelp.com/2024/03/building-data-abstractions-with-streaming-at-yelp.html
related: history architecture in 2016, Kafka based Billions of Messages a Day - Yelp’s Real-time Data Pipeline
Building Data Abstractions with Streaming at Yelp
In March 2024, Yelp shared insights into how they leverage streaming to create robust data abstractions for their offline and streaming data consumers. This blog post will summarize the key points from their article and provide some follow-up thoughts on the implementation.
Table of Contents
Introduction
Yelp relies heavily on streaming to synchronize enormous volumes of data in real-time. Their underlying data pipeline infrastructure manages millions of messages from various services, ensuring efficient data transformation for both offline and streaming data consumers.
Key Terminology
- Offline Systems: Data warehousing platforms like AWS Redshift for large-scale data analysis.
- Online Systems: High-performance SQL and NoSQL databases for real-time data access, such as MySQL and Cassandra.
Current Architecture
Business Properties Ecosystem
Business properties include attributes and features associated with Yelp businesses, stored in MySQL and Cassandra databases. Data is synchronized using MySQL Replication Handler and Cassandra Source Connector, pushing data to Kafka and then to Redshift for analysis.
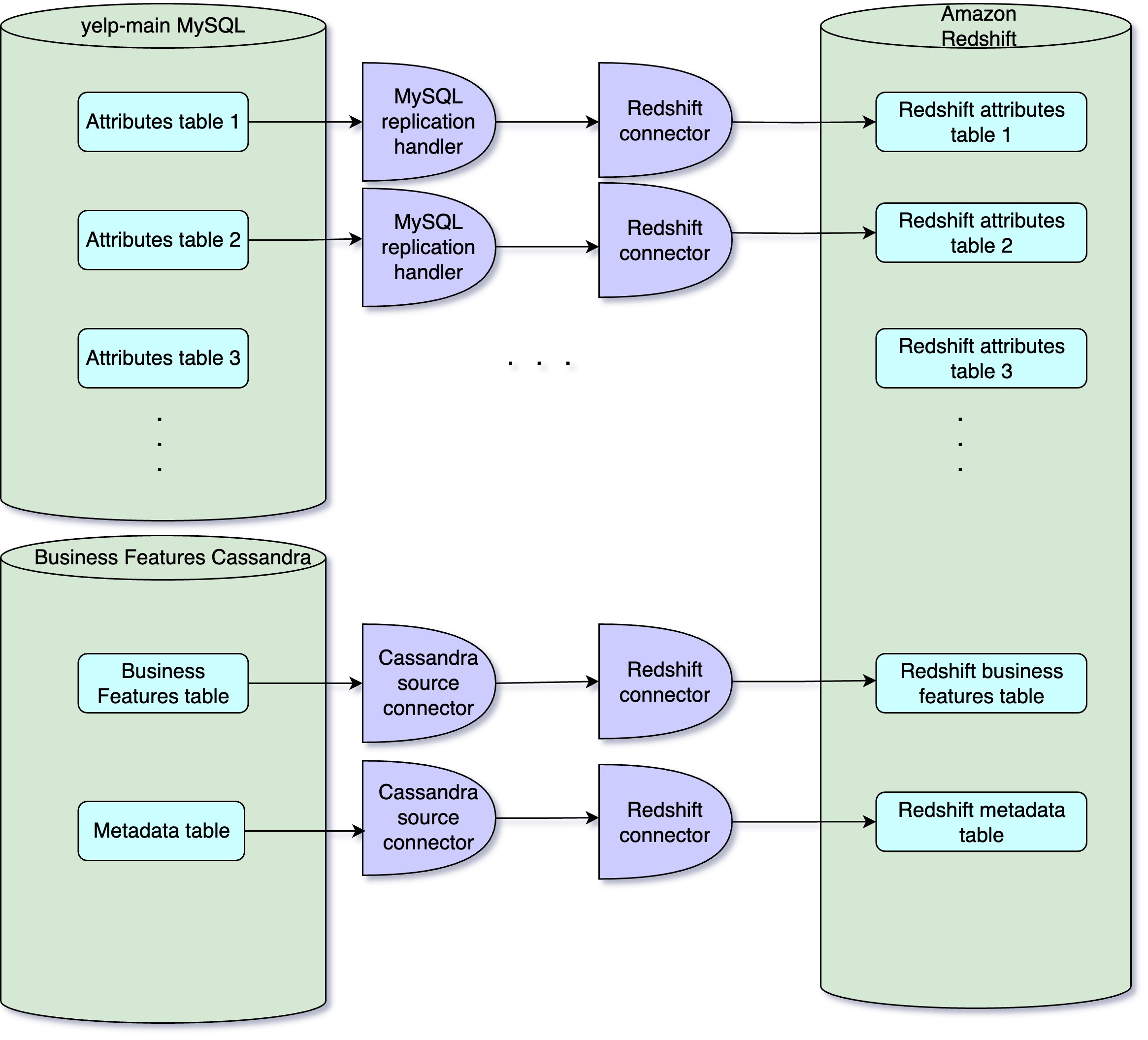
Challenges
- Weak Encapsulation: Clients must understand source data’s inner workings, weakening data encapsulation and leading to inconsistencies.
- Data Discovery and Consumption: Consumers face challenges in collecting data from multiple sources, adding complexity and cost.
- Maintenance: Schema changes in source databases necessitate changes in destination stores, causing disruptions.
Improved Implementation
Unified Data Abstractions
Yelp tackled the challenges by creating a unified stream that delivers business property data in a consistent format. They used Apache Beam and Flink for data transformation, creating a unified stream for Business Attributes and Features. This approach simplifies data discovery, reduces maintenance overhead, and ensures consistency across offline and streaming data consumers.
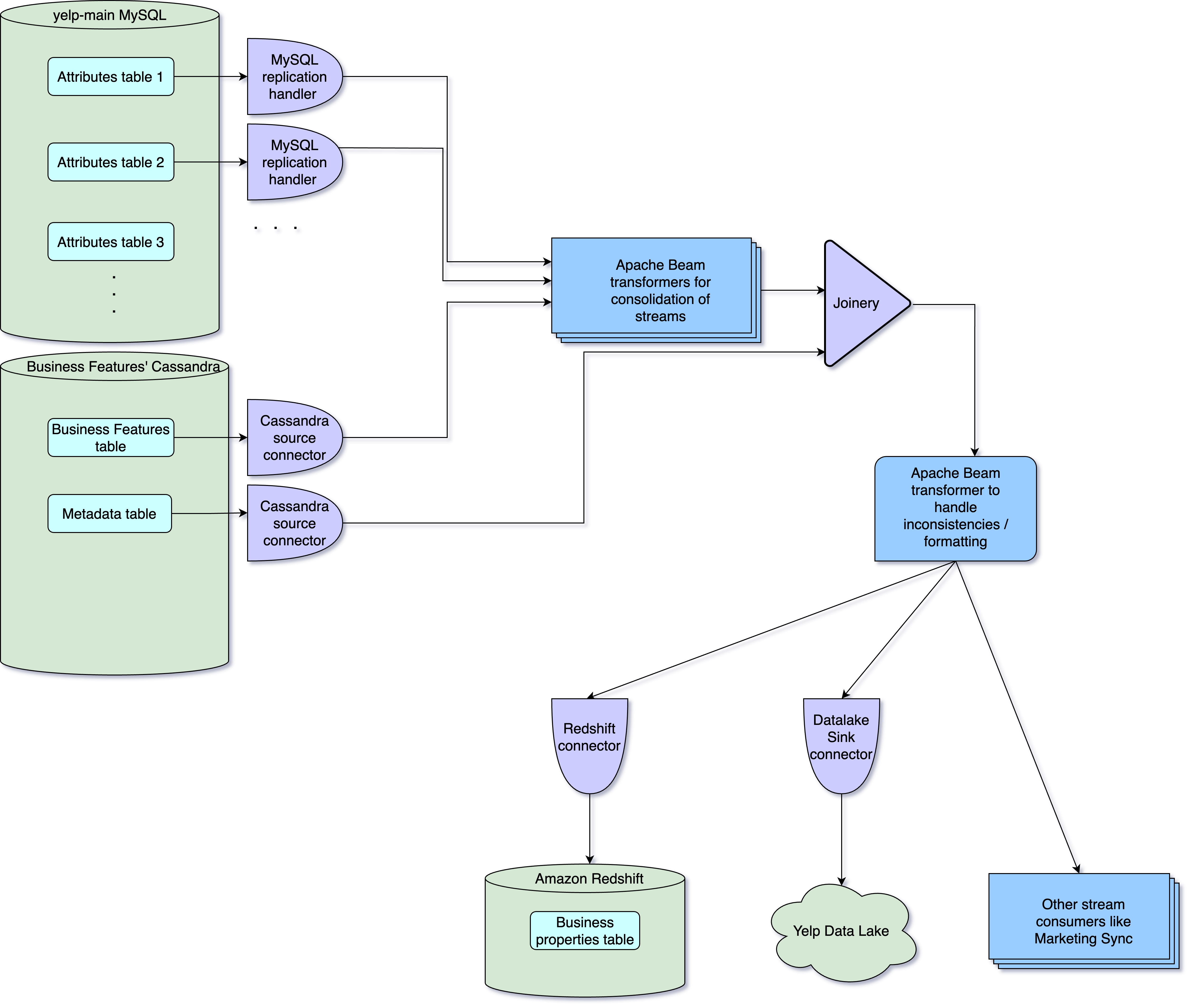
Conclusion
Yelp’s approach to building data abstractions with streaming provides a robust solution for managing data complexity and ensuring consistency. By leveraging their data pipeline infrastructure, Yelp can deliver data in a format suitable for both offline and streaming users, enhancing data accessibility and utility.
For more detailed insights, you can read the full article on Yelp Engineering Blog: Building Data Abstractions with Streaming at Yelp.