Slides
https://github.com/keypointt/reading/blob/master/spark/2017_spark_spring_SF_LinkedIn_graph.pdf
note
1. Graph Partition && Vertex Representation
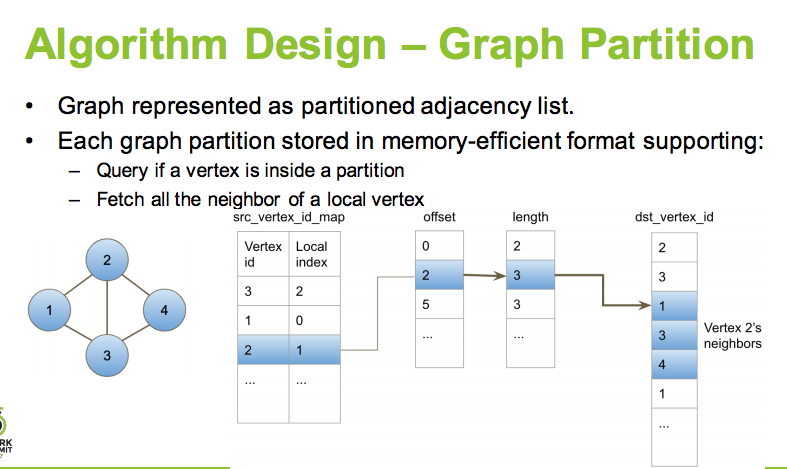
Here layered lookup table used: offset + length, and this can totally be transformed as a design question.
dst_vertex_idtable should be a global one, broadcasted among executors.
2. zipPartition operator while reduce shuffling
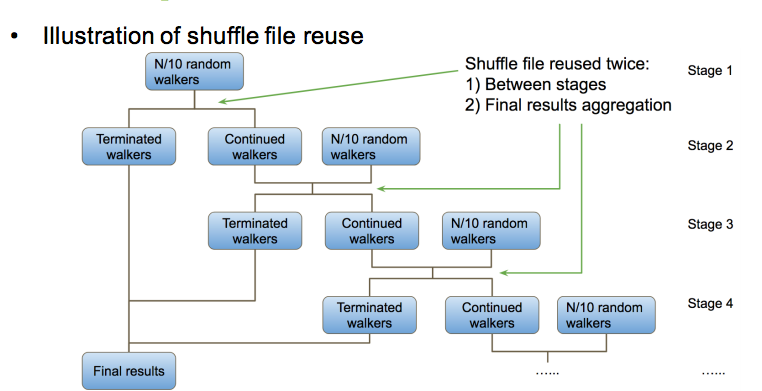
Start with part of walks, not all of them.
Spark’s zipPartition operator efficiently leverages the routing table.
And p% of the random walkers in each stage helps on co-locate results and reduce shuffle.
Reference: