Slides
https://github.com/keypointt/reading/blob/master/spark/2017_spark_spring_SF_FB_tuning.pdf
related blog: Apache Spark @Scale: A 60 TB+ production use case
note
1. Scuba: Diving into Data at Facebook
Paper: Scuba: Diving into Data at Facebook
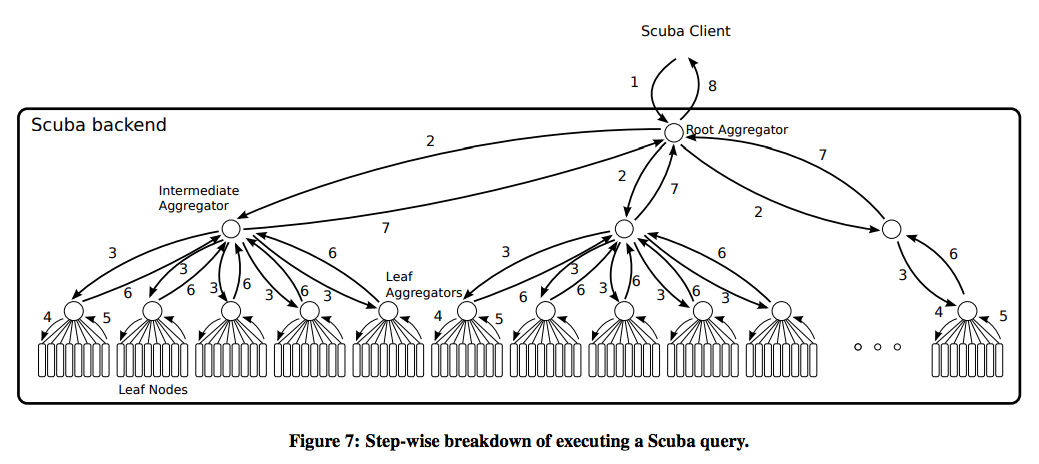
Data Model:
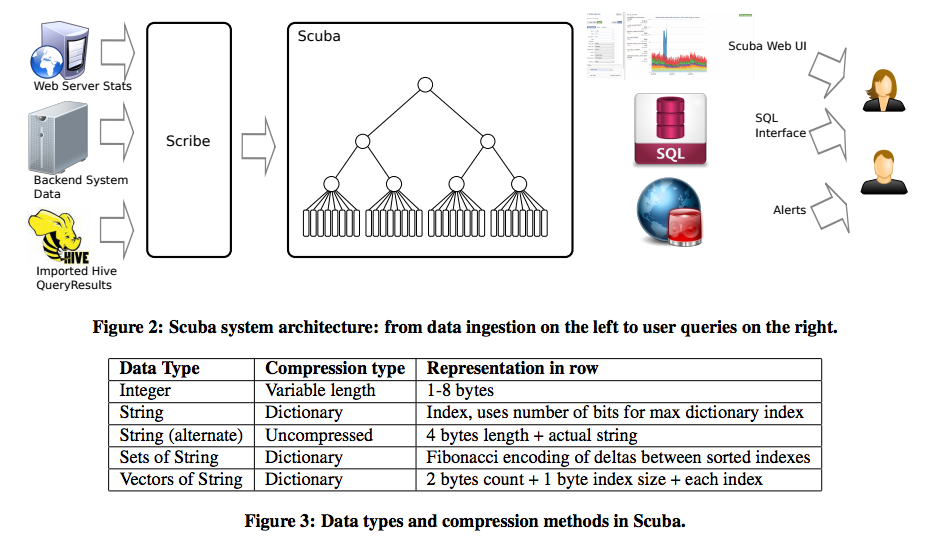
- Integers
- Strings
- Sets of Strings
- Vectors of Strings (ordered, for corresponds)
Note that floats are not supported; aggregation over floating point numbers on many leaves can cause too many errors in accuracy.
Instead, Scuba recommends that users choose the number of decimal places they care about, say 5
SPARK-19753: Remove all shuffle files on a host in case of slave lost of fetch failure
Avoid multiple retries of stages in case of Fetch Failure.
If we remove all the shuffle files on that host, ** on first fetch failure **, we can rerun all the tasks on that host in a single stage retry.
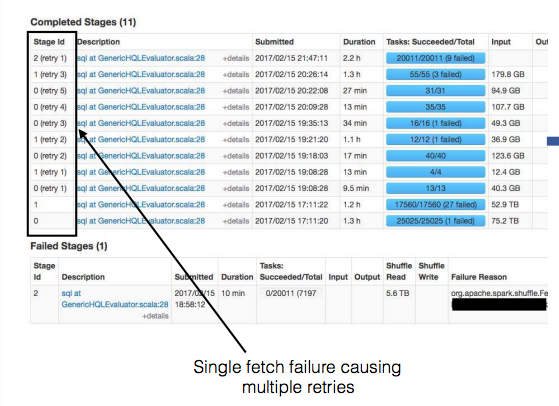
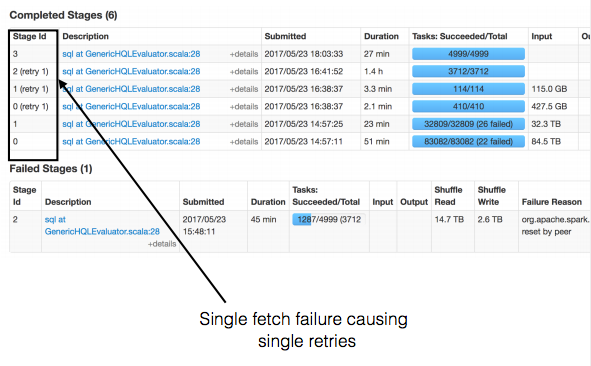
[1]. To update MapOutputTracker with fetch failure, mapStatuses(mapId) = null in MapOutputTracker.scala
/**
* Removes all shuffle outputs which satisfies the filter. Note that this will also
* remove outputs which are served by an external shuffle server (if one exists).
*/
def removeOutputsByFilter(f: (BlockManagerId) => Boolean): Unit = synchronized {
for (mapId <- 0 until mapStatuses.length) {
if (mapStatuses(mapId) != null && f(mapStatuses(mapId).location)) {
_numAvailableOutputs -= 1
mapStatuses(mapId) = null
invalidateSerializedMapOutputStatusCache()
}
}
}[2]. In DAG scheduler, only unregister the outputs related to the exact executor(instead of the host) on a FetchFailure.
2.1 when case FetchFailed(bmAddress, shuffleId, mapId, reduceId, failureMessage) =>
2.2 then check if (env.blockManager.externalShuffleServiceEnabled && unRegisterOutputOnHostOnFetchFailure), remove and unregister
removeExecutorAndUnregisterOutputs(
execId = bmAddress.executorId,
fileLost = true,
hostToUnregisterOutputs = hostToUnregisterOutputs,
maybeEpoch = Some(task.epoch))
[3]. Key function to remove/unregister is removeExecutorAndUnregisterOutputs(...)
3.1 remove from bm blockManagerMaster.removeExecutor(execId)
3.2 remove from track map, mapOutputTracker.removeOutputsOnHost(host) for host and mapOutputTracker.removeOutputsOnExecutor(execId) for executor
SPARK-20014: Optimize mergeSpillsWithFileStream method
[1]. Convert to InputStream
- final InputStream[] spillInputStreams = new FileInputStream[spills.length];
+ final InputStream[] spillInputStreams = new InputStream[spills.length];
[2]. Construct output stream
final OutputStream bos = new BufferedOutputStream(
java.nio.file.Files.newOutputStream(outputFile.toPath()),
outputBufferSizeInBytes);
[3]. Tunnel input to output
ByteStreams.copy(partitionInputStream, partitionOutput);
SPARK-15074: Cache shuffle index file to speedup shuffle fetch
- pain: Shuffle fetch on large intermediate dataset is slow because the shuffle service open/close the index file for each shuffle fetch.
- solution: This change introduces a cache for the index information so that we can avoid accessing the index files for each block fetch
shuffleIndexCache = CacheBuilder.newBuilder()
.maximumSize(indexCacheEntries).build(indexCacheLoader);Reference: