Article-1: Meet Michelangelo: Uber’s Machine Learning Platform
- ML-as-a-service platform, end-to-end ML workflow
- seamlessly build, deploy, and operate machine learning solutions
- scalable model training and deployment to production serving
- speed up the path from idea to first production model and the fast iterations that follow
- manage data, train, evaluate, and deploy models, make predictions, and monitor predictions
Use case: UberEATS estimated time of delivery model
- Model: use gradient boosted decision tree regression models
- Features:
- request (e.g., time of day, delivery location)
- historical features (e.g. average meal prep time for the last seven days)
- near-realtime calculated features (e.g., average meal prep time for the last one hour)
- Query: invoked via network requests by the UberEATS microservices
- other metrics to predict: search rankings, search autocomplete, and restaurant rankings
System architecture
- Tech stack: HDFS, Spark, Samza, Cassandra, MLLib, XGBoost, and TensorFlow
- Kafka brokers that aggregate logged messages
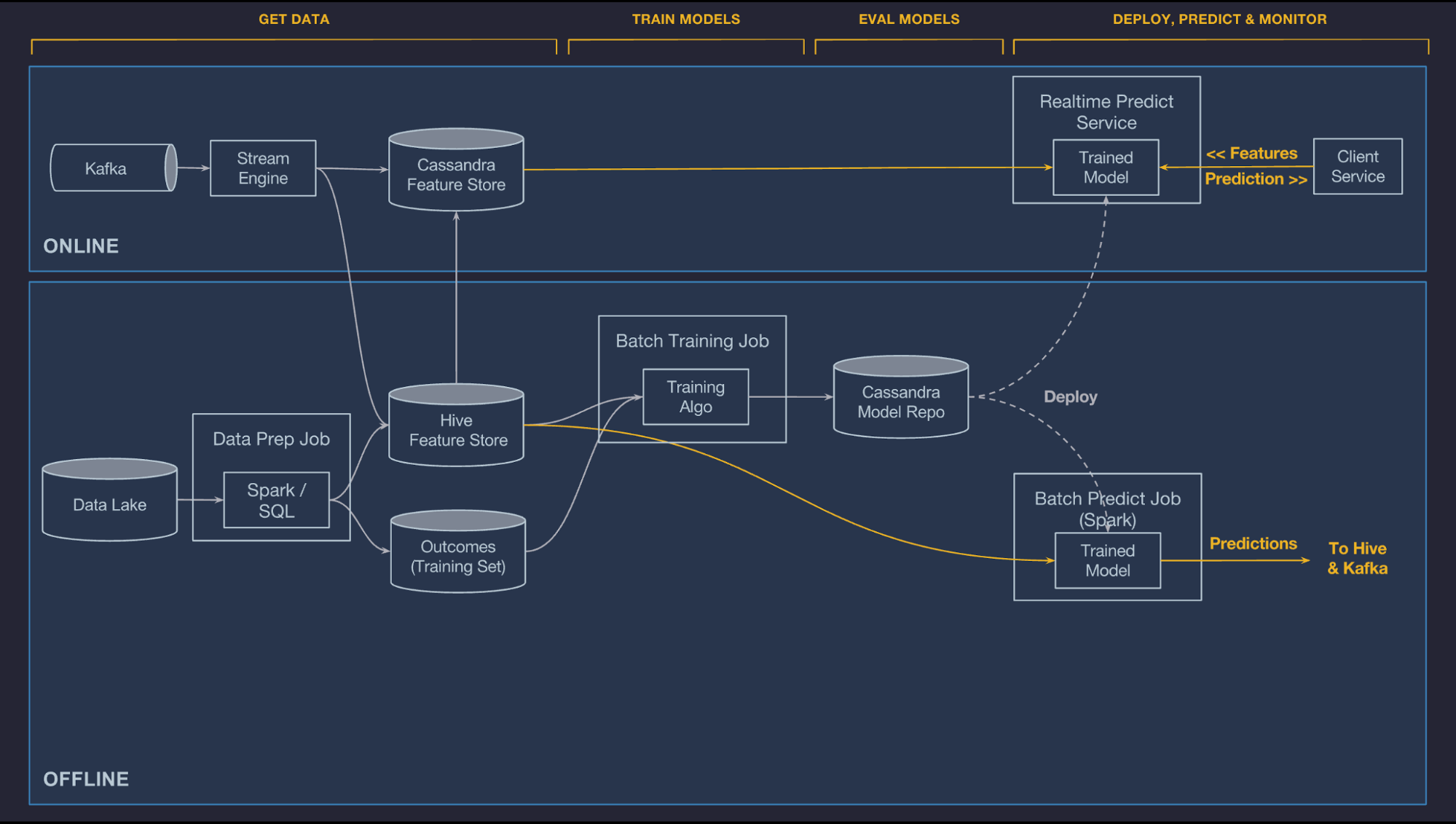
Workflow:
1 . Manage data
- integration with the company’s data lake or warehouses (@Xin: so I guess ETL and data cleaning is partially done at this part)
- offline pipelines: feed batch model training and batch prediction jobs
- HDFS data lake and is easily accessible via Spark and Hive SQL
- publish features to centralized Feature-Store and shared across teams (@Xin: delta lake?)
- approximately 10,000 features in Feature Store
- online pipelines: feed online, low latency predictions
- allow features needed for online models to be precomputed and stored in Cassandra
- Batch precompute
- Near-real-time compute
- publish relevant metrics to Kafka
- then run Samza-based streaming compute jobs to generate aggregate features at low latency
- then written directly to Cassandra for serving
- for read at low latency at prediction time
- allow features needed for online models to be precomputed and stored in Cassandra
- data management layer: to share, discover, and use a highly curated set of features (@Xin: so I guess multi-tenant for cross team collaboration)
2 . Train models
- support offline, large-scale distributed training of
- decision trees, linear and logistic models, unsupervised models (k-means), time series models, and deep neural networks.
- evaluation report: model performance metrics (e.g., ROC curve and PR curve) are computed and combined
- saved back to our model repository for analysis and deployment (@Xin: maybe also model versioning)
- parent model and child model (or sister model)
- training one model per city, and shift to another model only change city name
- falling back to a country-level model
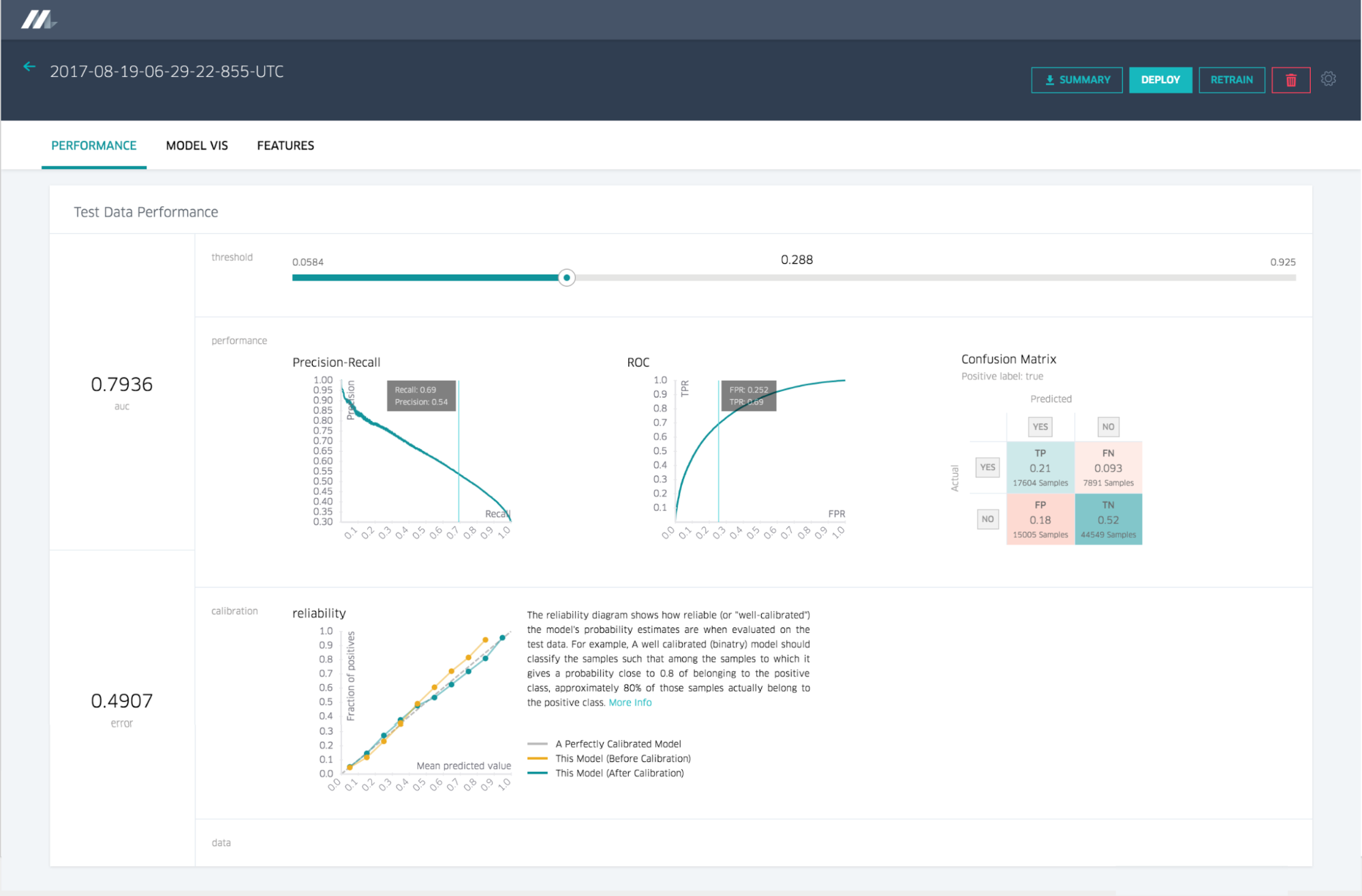
3 . Evaluate models and Feature report
store a versioned object in our model repository in Cassandra that contains a record of below
and feed to UI to display
Who trained the model
Start and end time of the training job
Full model configuration (features used, hyper-parameter values, etc.)
Reference to training and test data sets
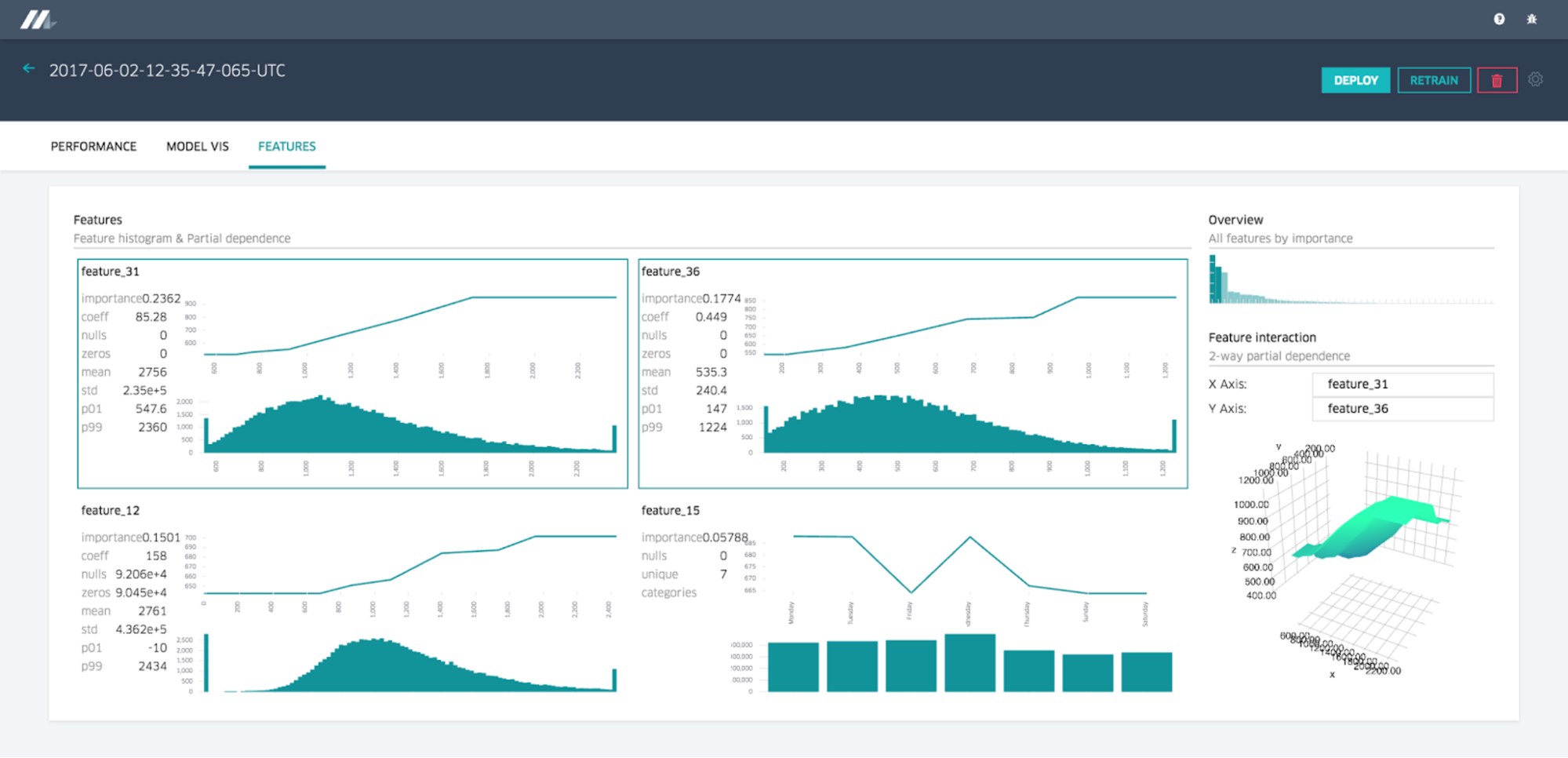
Distribution and relative importance of each feature
Model accuracy metrics
Standard charts and graphs for each model type
(e.g. ROC curve, PR curve, and confusion matrix for a binary classifier)
Full learned parameters of the model
Summary statistics for model visualization
4 . Deploy models
- Offline deployment
- Online deployment
- Library deployment: packaged in a ZIP archive and copied to the relevant hosts
- (@Xin: similar to AWS-Lambda’s Layer concept)
- safe transitions from old models to new models
- a model is identified by its UUID and an optional tag (or alias)
- client request with feature vector and the model UUID (or model tag) that it wants to use
- side-by-side A/B testing of models
- deploy competing models either via UUIDs or tags
- then use client service to send portions of the traffic to each model
- then track performance metrics
- scalability
- online models: more hosts, , add more Spark executors, horizon scale
- offline: whatever working, who cares as long as spill batch result
5 . Make predictions
- online models, the prediction is returned to the client service over the network
- offline models, the predictions are written back to Hive
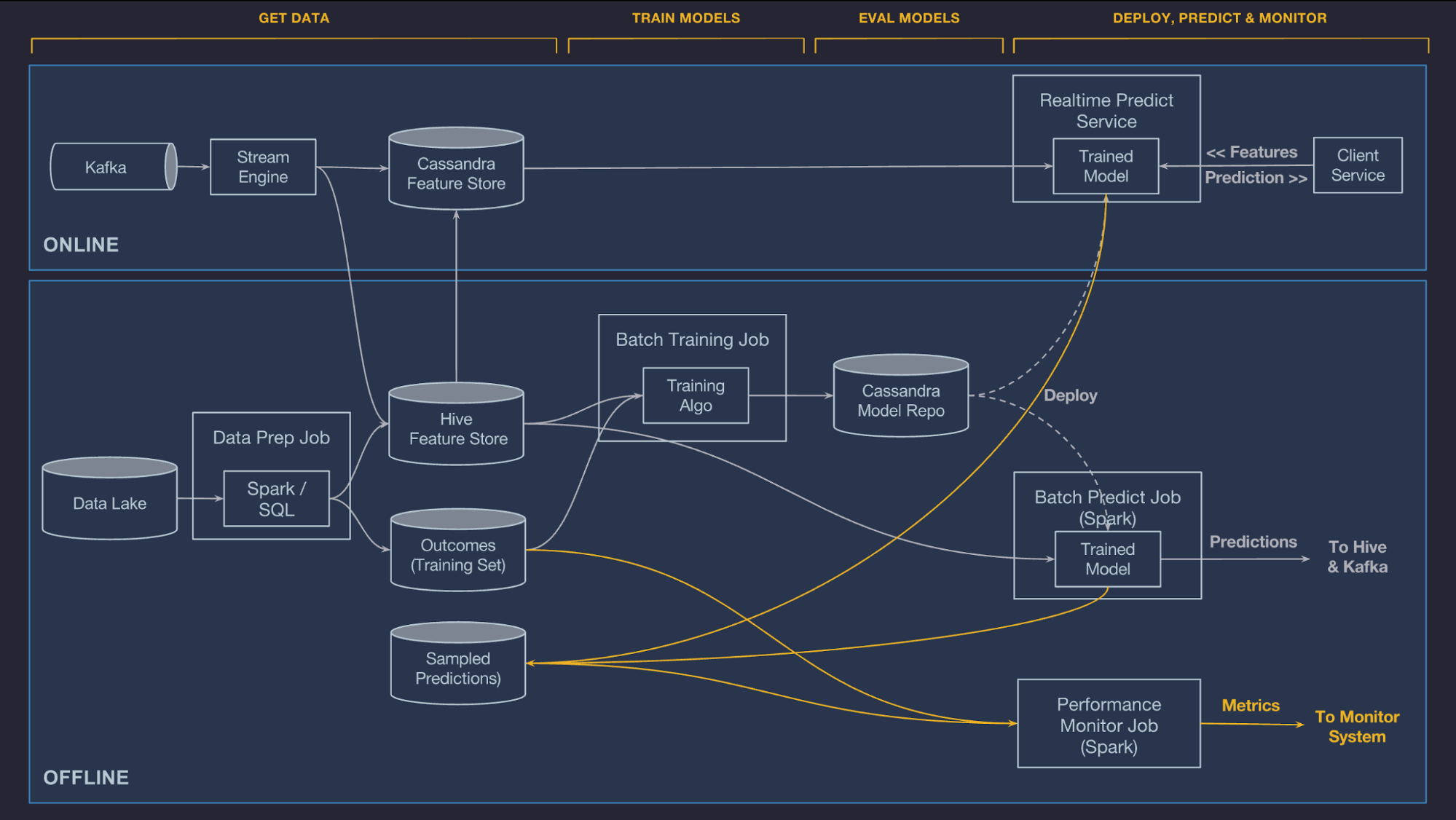
6 . Monitor predictions
- log and optionally hold back a percentage of the predictions that it makes
- then later join those predictions to the observed outcomes (backward propagation)
7 . UI - who cares…lol
8 . AutoML - data scientists having 1-million reason why auto-ml not working out
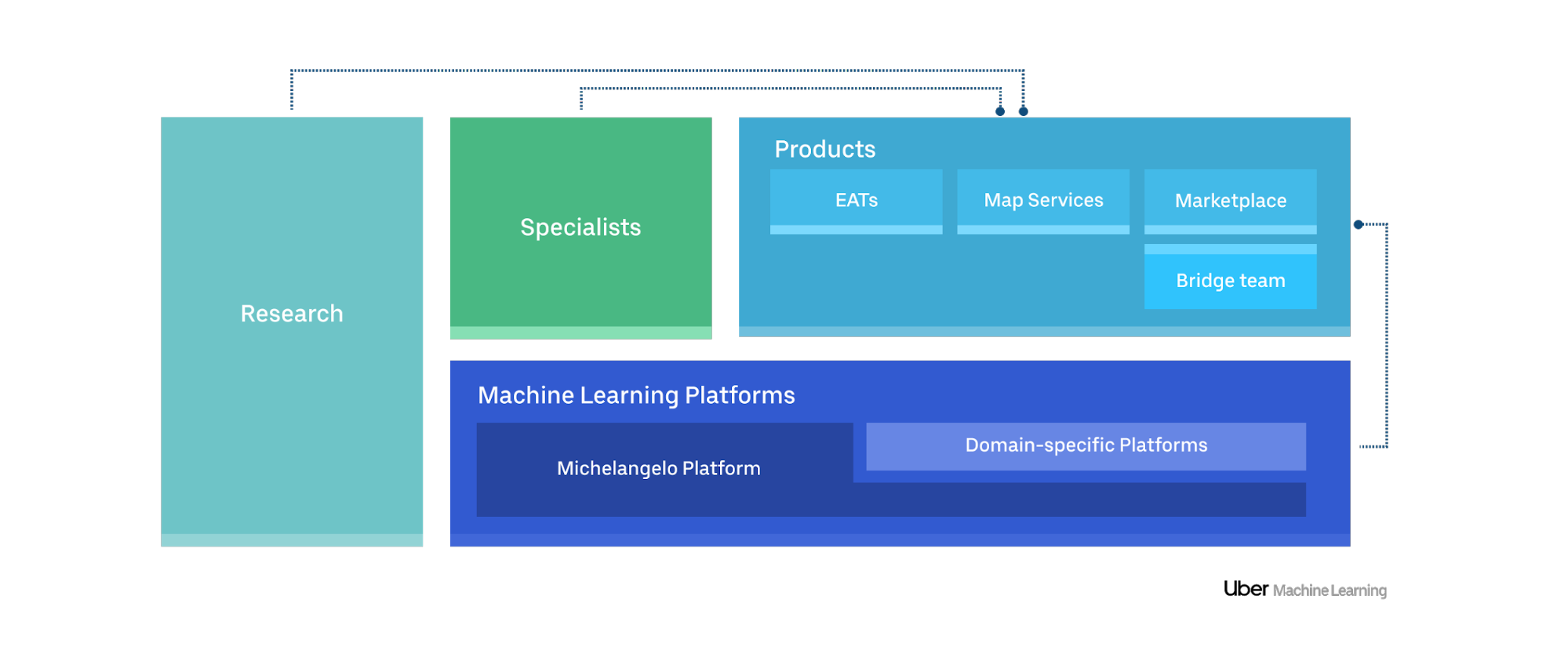
Closing - @Xin: Uber ml platform, pretty decent, covering all aspects as of ml engineering
Article-2: Scaling Machine Learning at Uber with Michelangelo
@Xin: basically this article didn’t touch technical scale part, more of cross team collaborations. I guess, it’s built on top of AWS/Azure/GoogleCloud, so utilizing existing scaling solution and not re-inventing the “scaling” wheel.
- core value: “zero-to-one speed” or “time-to-value speed”
- explosion of ML deployments, thousands of models deployments
- batch training and productionizing batch prediction jobs
- => feature store
- => notebook integrations
- => partitioned models
- components and integrations
Use cases
- Uber Eats: Recommending for the Marketplace
- Marketplace Forecasting: predict where rider demand and driver-partner availability will be at various places and times in the future
- Customer Support: ticket handling (@Xin: AWS-Connect concept)
- recommend support ticket responses (Contact Type and Reply) to customer support agents,
- with Contact Type being the issue category that the ticket is assigned to and Reply the template agents use to respond
- (@Xin: so, basically binary classification, or multi-class classification)
- Ride Check: detect possible crashes (@Xin: anomaly detection)
- Estimated Times of Arrival (ETAs): segment-by-segment routing system that is used to calculate base ETA values
- Self-Driving Cars: training of large models across a large number of GPU machines (@Xin: Tesla…lol)
Process
- product organizations (e.g., the Uber Eats or Marketplace teams) own the launch processes around their ML models
- internal ML conference called UberML
- Manage data: feature store
- Train models: GPU clusters, CPU clusters
- Model evaluation: model comparison feature
- machine learning as software engineering
Uber job description
@Xin: so job requirement is pretty much aligned with above tech stack and system design. and should be a job posting for data platform team.
[Uber] Sr Software Engineer - ML
- Own the End to End of product - ML model pipeline & backend system design, implementation, AB testing, and rollout.
- Minimum of 4 years of engineering experience in one or more of the following areas: machine learning, search, ranking, recommendation systems, pattern recognition, data mining, or artificial intelligence
- Machine learning domain knowledge
- bias-variance tradeoff,
- exploration/exploitation
- understanding of various model families, including
- neural net, decision trees, bayesian models, instance-based learning, association learning, and deep learning algorithms.
- You have experience using machine learning libraries or platforms, including Tensorflow, Caffe, Theanos, Scikit-Learn,or ML Lib for production or commercial products
- Experience developing complex software systems scaling to millions of users with production quality deployment, monitoring and reliability
[Placeholder]
Paper: https://papers.nips.cc/paper/5656-hidden-technical-debt-in-machine-learning-systems.pdf
Reference:
- Article-1: https://eng.uber.com/michelangelo-machine-learning-platform/
- Article-2: https://eng.uber.com/scaling-michelangelo/
- Uber Eats Recommending: https://eng.uber.com/uber-eats-recommending-marketplace/
- Customer Support Ticket Assistant (COTA) System: https://eng.uber.com/cota-v2/