Slides
https://github.com/keypointt/reading/blob/master/spark/2017_spark_spring_SF_IoT_stack.pdf
note
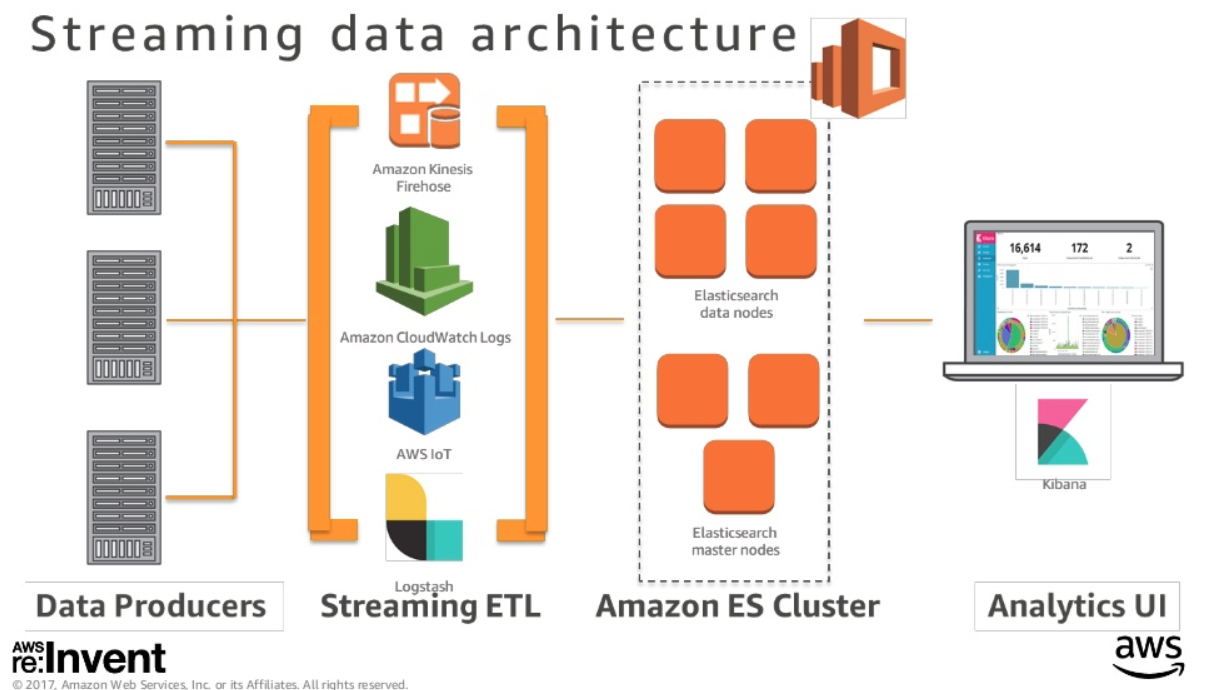
AWS ES workflow
- Kinesis Firehose
- CloudWatch
- IoT
- LogStash
Add durability
- dedicated master instances improve cluster stability
- basically is to have some back master instance, to avoid SPOF as master node
- zone awareness (cross AZ)
Size the domain
- Best practises
- shards should be < 50GB
- initial shard count = index size / 40GB
- active shards per instance = vCPUs
- enable replica in prod invironment
Example: 2TB corpus will need 50 shards: 2TB / 40GB = 50 shards
- write heaving (streaming) V.S. read heavy
- concern: concurrency
- write: to all replica and shards
- read: from one of each shard * concern: unbalanced storage (uni distribution hash)
Reference:
- https://www.slideshare.net/AmazonWebServices/abd302realtime-data-exploration-and-analytics-with-amazon-elasticsearch-service